TL;DR: Sometimes, writing an intermediate result to disk and then reading it back again is faster than checkpointing or unoptimized caching!
At Spokeo, we use Spark on Amazon EMR to build data from our data lake into documents that can be consumed by our backend services and eventually shown in the frontend. Therefore, many of our ETL jobs are concerned with producing one result at the end of a script. Getting to the end may involve many heavy calculations, e.g. windowing on id, before joining back to the main dataframe. In some cases, the main dataframe is later split into two with filters, then something expensive is done to the smaller dataframe before we union them back again.
For our purposes, storing intermediate results is desirable for two reasons.
Who's Calling Me?
Search any phone number to learn more about the owner!
First – storing the intermediate result improves fault tolerance. If we spend a lot of time and work doing a complex transformation and something downstream of it fails, storing the intermediate result prevents us from having to start again.
Second – some methods of storing intermediate results truncate the lineage of the data transformation. This can help prevent applications from crashing due to memory exhaustion. This is a risk with applications that process a lot of data through complex and expensive transformations.
Methods that come immediately to mind are `.cache` and `checkpoint`. Let’s explore the different usages in context of pyspark ETL.
Cache and Checkpoint Variations
Cache: Quote: “If you’re executing multiple actions on the same DataFrame then cache it.” Common advice is to follow `df.cache()` with an action `df.count()` to trigger caching right away. Can we still trigger cache with one action only at the very end of the script?
Cache and count: The intuition behind this is that counting a dataframe imperatively forces its contents into memory. This is a similar intuition to calling `df.show()`, which may only cache a fraction of the dataframe, whereas `df.count()` caches 100%.
Checkpoint: `checkpoint` is used to truncate logical plans. It’s useful when the logical plan becomes very large, e.g. in iterative unions causing out of memory errors (ref). This is expected to be slower than cache as it commits the result to disk. There’s rdd checkpoint API (ref) and dataframe checkpoint API (ref). We will try the latter.
Cache and checkpoint: There is a warning on the RDD checkpoint API: “It is strongly recommended that this RDD is persisted in memory, otherwise saving it on a file will require recomputation.” So we will try cache and checkpoint, and look out for signs of skipped recomputation.
Writing and then reading a dataframe back as itself (using parquet storage): While in theory this produces an extremely clean truncation of the logical plan, this may be less performant due to writing to disk.
Experiment
We will try these four approaches in our crazy ETL script below. Here is our flow:
- Do something expensive first (self-join)
- Store the intermediate layer with different methods
- Split the dataframe with filters
- Union them back to write.
We will run this locally in pyspark 2.4.4, inspect SparkUI, and run each method 20 times to compare performance. We will take measurements in pyspark 3.0.1.


Performance is measured like this:

Results
SparkUI Observations
It may be too crowded to post all the screenshots here. We will describe only differences in words and leave here some screenshots of interest.
Test Control
In `test_control` we see the filter pushdown where filters are applied first before each self join. So we get four filters, two self joins, and one final union.
Test Cache
In `test_cache` we see a plan that follows our code more closely, performing the self join first, caching the result second (see green dot), then applying filters before final union.
Test Cache and Count
In `test_cache_and_count` we see the same plans, logical and physical as for `test_cache`. But here we have two jobs! Job0 to count – it includes one more stage to aggregate compared to Job0 in `test_cache`; Job1 to parquet – it resumes work from the green dot in the last stage.
Test Checkpoint
In `test_checkpoint` we see the same parsed logical plan but shorter Optimized Logical Plan and Physical Plan. It takes three jobs to complete: Job0 to checkpoint the self-join; Job1 to checkpoint again but skipping the first two stages; Job2 to parquet runs from beginning to finish like in `test_control` without skipping any stages.
Test Cache and Checkpoint
In `test_cache_and_checkpoint` we see the same plans as for `test_cache`, except we have three jobs here. Job0 to checkpoint the self join; Job1 to checkpoint again but now resumes work from green dot, Job2 to parquet resumes work from the green dot.
Test Write and Read
In `test_write_and_read` we see the final output plan reflects only work from the intermediate result. Job0 to write to intermediate, Job1 to read, Job2 to final parquet.
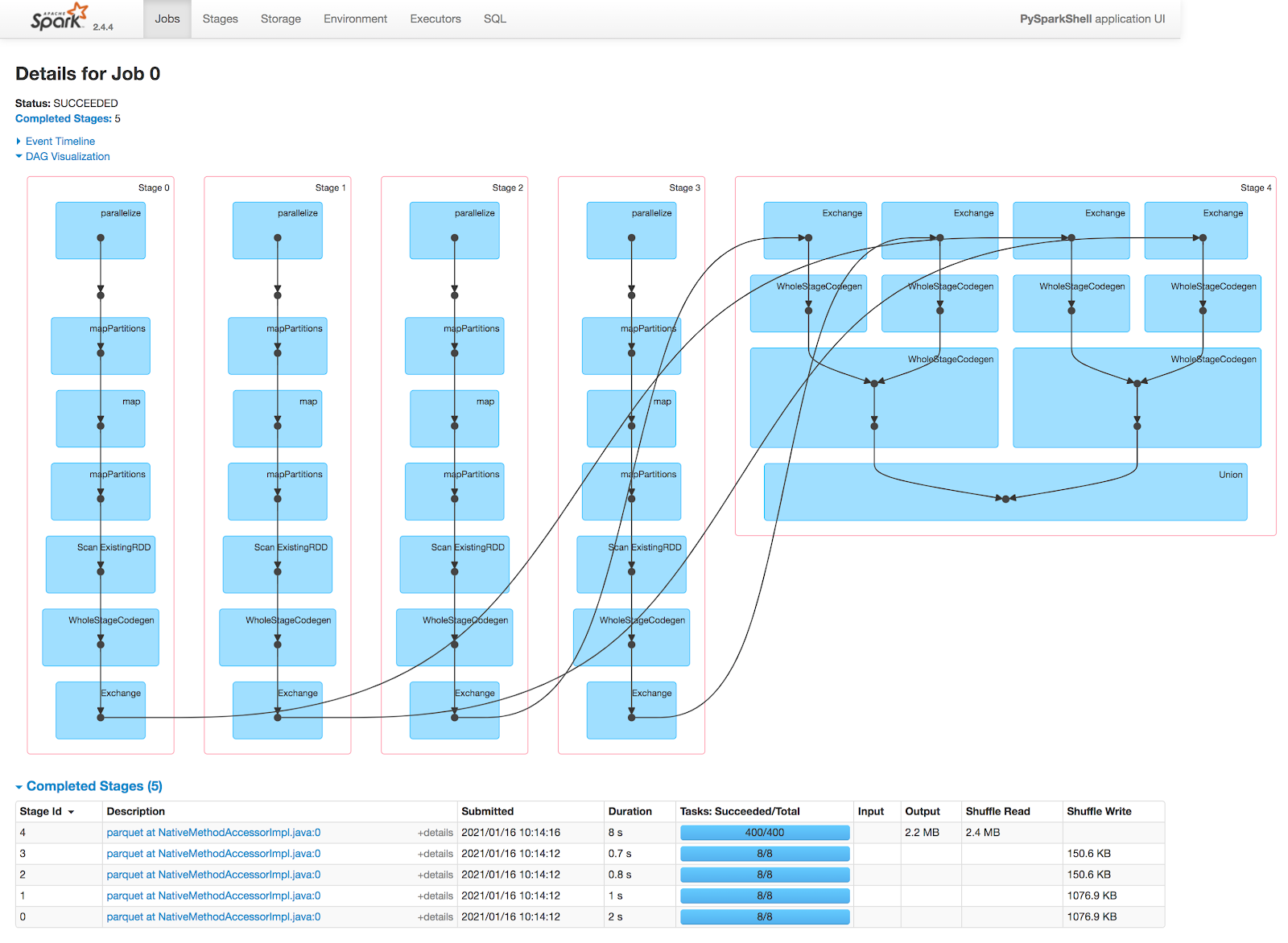
[CAPTION] Figure 1: Control DAG
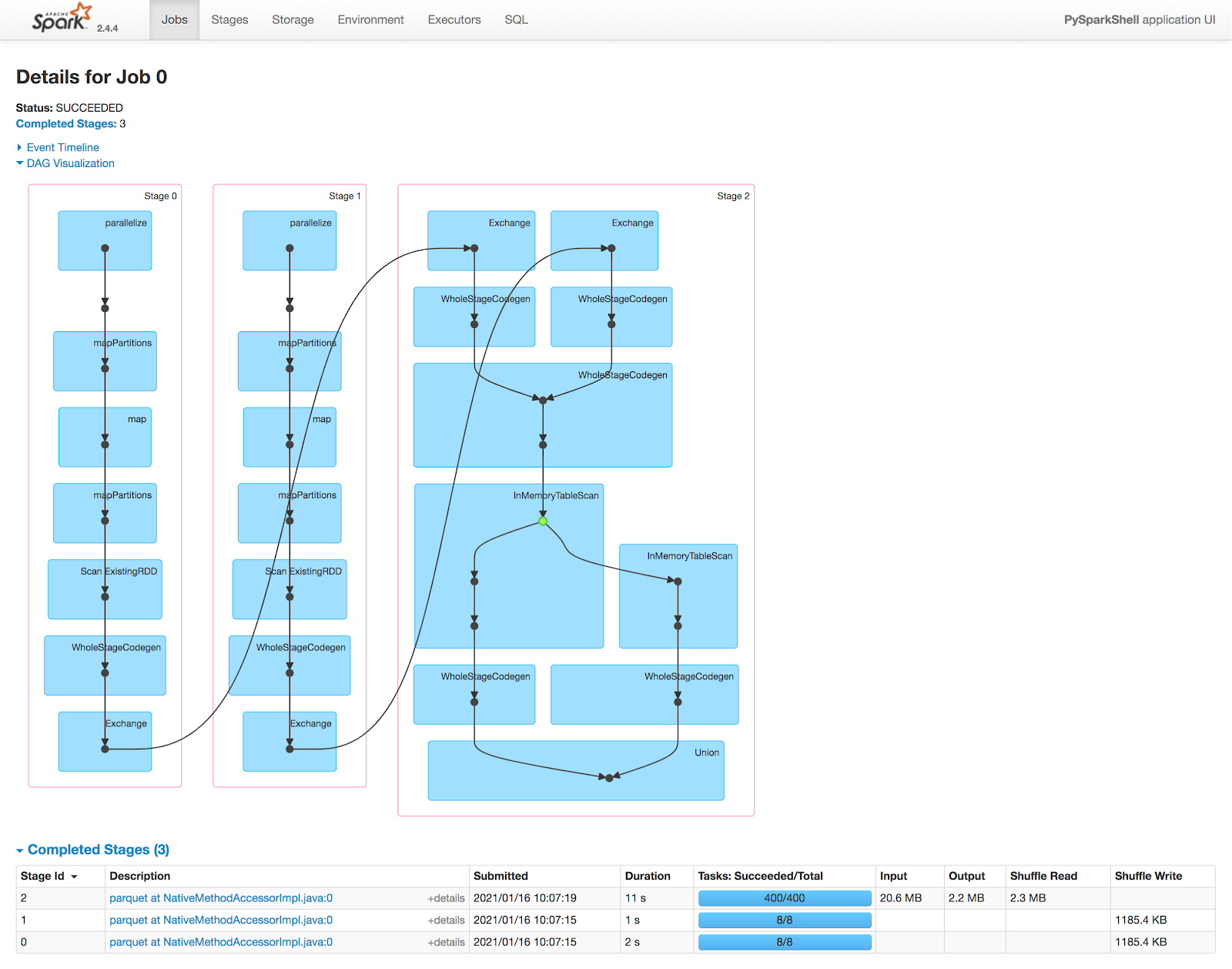
[CAPTION] Figure 2: Cache Job DAG
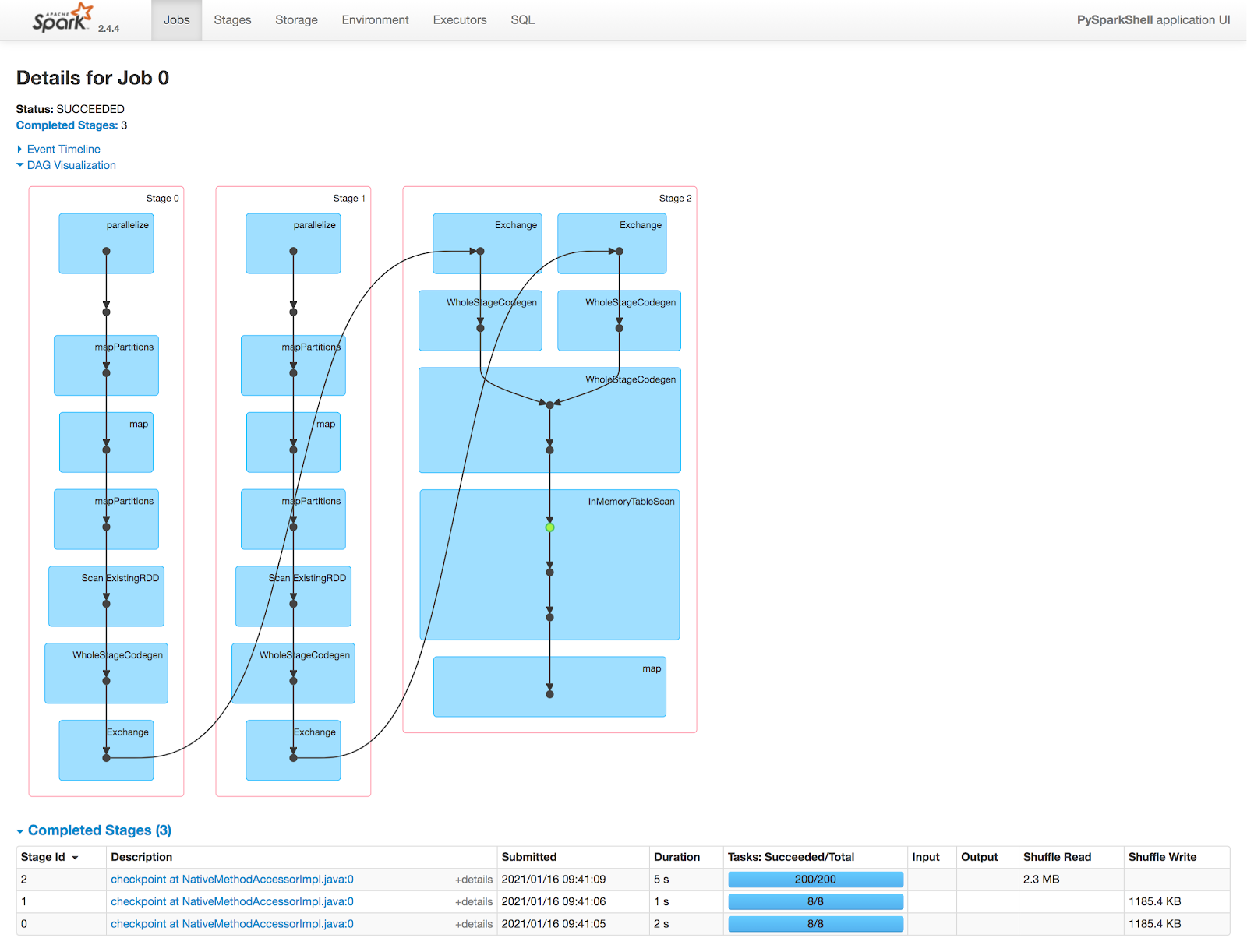
[CAPTION] Figure 3: Checkpoint Job0 DAG
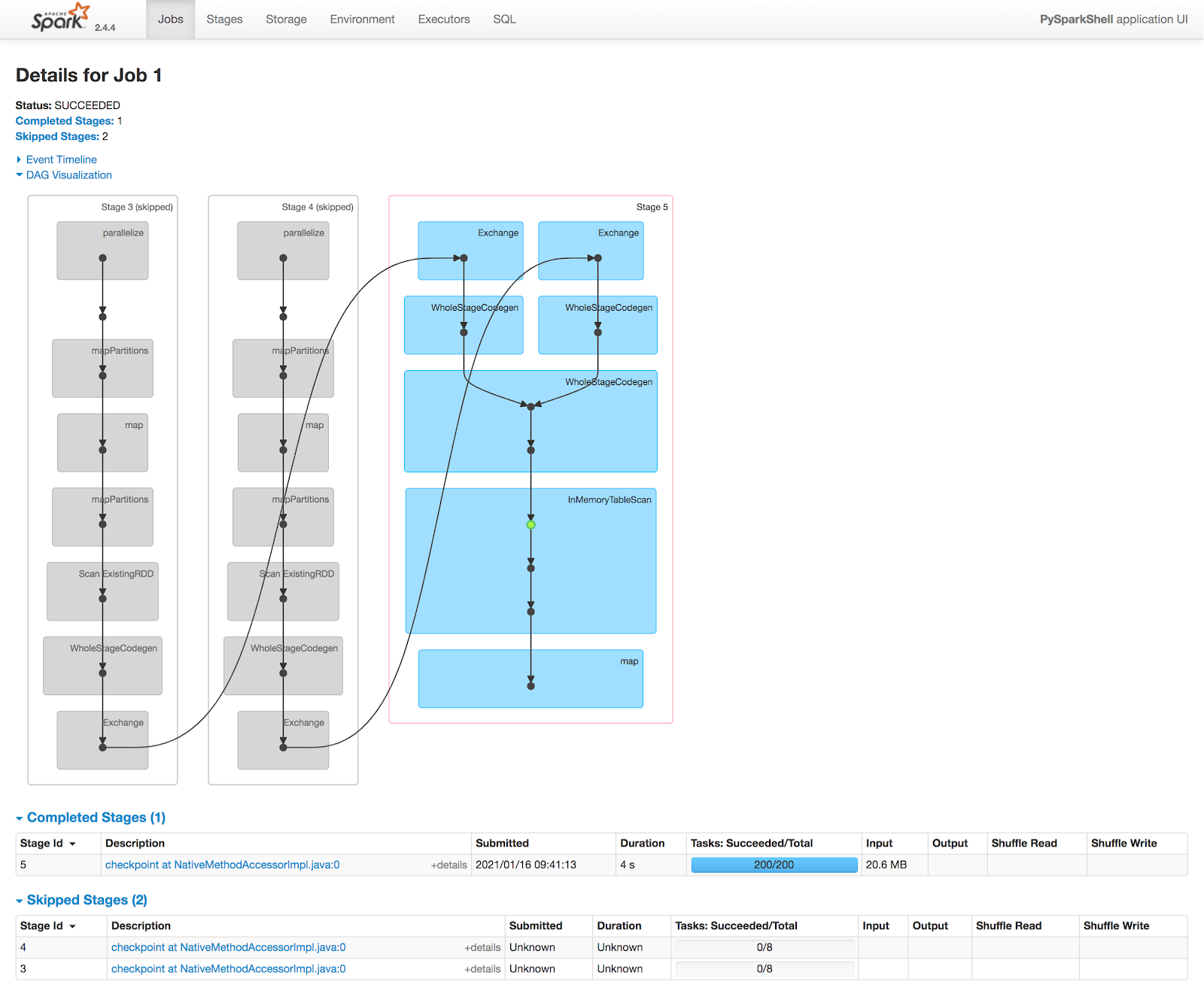
[CAPTION] Figure 4: Checkpoint Job1 DAG
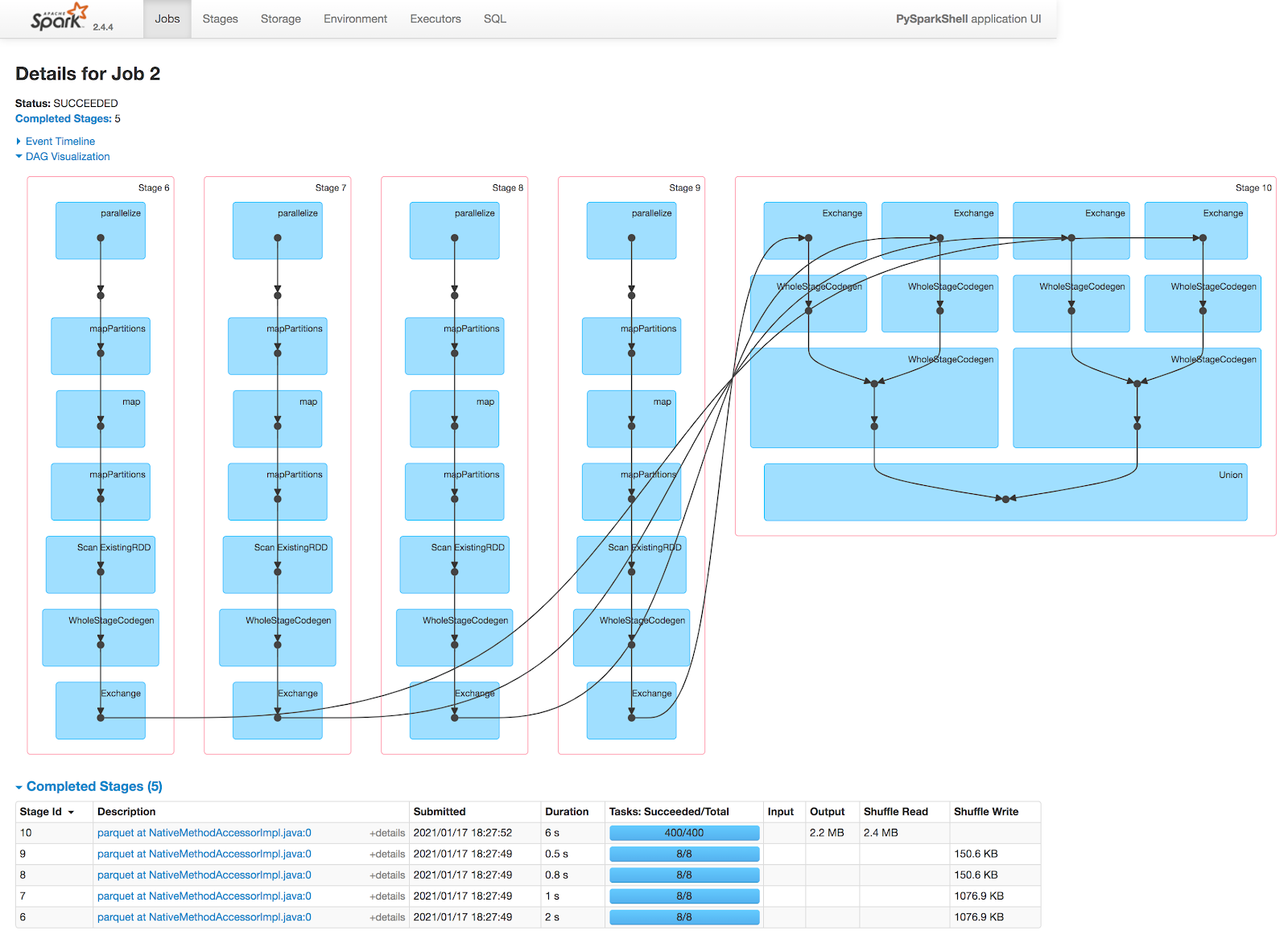
[CAPTION] Figure 5: Checkpoint Job2 DAG
Performance
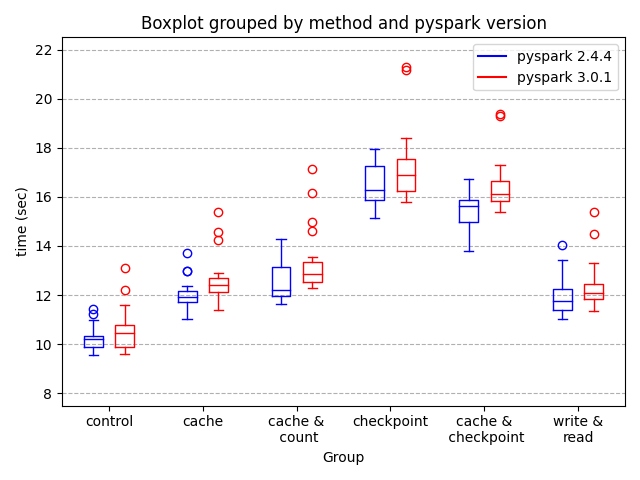
[CAPTION] Figure 6: Time to finish by intermediate storage methods in spark 2.4.4 and 3.0.1
Figure 6 shows performance per test group in seconds; each box represents 20 measurements.
Discussion
The filter pushdown has helped `test_control` to achieve the best time. This means that even though it’s good to store products from a long compute for faster discovery, we still need to be careful about introducing stop points as they block catalyst optimizations (any listed here) of the general flow. We should not insert cache point here to fork data.
Simple `cache` performs a bit better than `cache and count` This dispels the need to count right away after cache. Green dot in `cache` DAG confirms that intermediate is saved to memory and utilized.
`write and read` performs comparably to `cache`! Note `cache` here means `persist(StorageLevel.MEMORY_AND_DISK)`, see pyspark 2.4.4 ref. `cache` not doing better here means there is room for memory tuning. See guide. Tuning parameters include using Kryo serializer (a high recommendation), and using serialized caching, e.g. MEMORY_AND_DISK_SER, to reduce footprint and GC pressure. The same guide on garbage collection here: “ when Java needs to evict old objects to make room for new ones, it will need to trace through all your Java objects and find the unused ones.”
`write and read` via parquet is a good alternative to using `df.checkpoint`. It is faster, lets us control how we want to read (hdfs or s3), and write. We can avoid rework by `df.write.mode(“ignore”)` in a subsequent run! Another benefit is that it relieves memory pressure from processes that may have memory leaks (pandas udfs) Note we do need to avoid special characters in column names when storing to parquet.
`checkpoint` results confirm the recomputation that takes place. Recomputation is reduced in `cache and checkpoint` where work is resumed from the green dot. However, both checkpoint methods don’t break the lineage as cleanly as `write and read`. Lineage is still preserved in both parsed logical plans.
To fully enjoy the benefits of storing intermediate results in a way that writes to disk, it is important to use a cluster architecture with strong rack locality for storage (for example, using a core instance type in EMR that has attached storage).
Takeaways
Here are the key takeaways:
- Insert intermediate points with caution as it may block Catalyst optimizations
- Look for opportunities to apply filters early when introducing intermediate points
- Invest time in memory tuning when using cache, else use write and read via parquet
- For our purposes, write and read is as good as, if not better than, checkpoint